在这篇文章中,作者首先介绍了一下神经网络、RNN和LSTM的基本概念,然后举例对比了三种网络的性能,并且进一步讲解了LSTM。
LSTM是神经网络一个相当简单的延伸扩展,而且在过去几年里取得了很多惊人成就。我第一次了解到LSTM时,简直有点目瞪口呆。不知道你能不能从下图中发现LSTM之美。
先简单介绍一下神经网络和LSTM。
神经网络
假设我们有一个来自电影的图像序列,然后想用一个活动来标记每张图像。例如这是一场打斗么?角色在交谈?角色在吃东西?
应该怎么做?
一种方法是忽略图像的顺序属性,把每张图片单独考虑,构建一个单张图片的分类器。例如,给出足够的图片和标签:
算法首先学习检测形状、边缘等低级模式
在更多数据的驱动下,算法学会将低级模式组合成复杂形态,例如一个椭圆形上面有两个圆形加一个三角形可以被认为是人脸
如果还有更多数据,算法会学到将这些高级模式映射到活动本身,例如有嘴、有牛排、有叉子的场景可能是吃饭
这就是一个深度神经网络:得到一个图像输入,返回一个活动输出。
神经网络的数学原理如图所示:
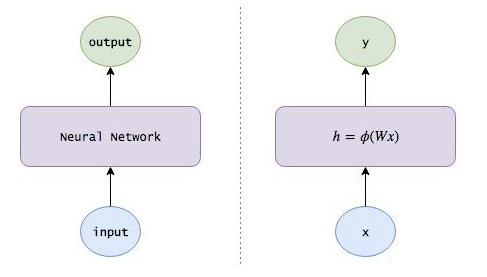
用RNN记住信息
忽略图像的顺序可以算是初步的机器学习。更进一步,如果是一幕海滩的场景,我们应该在后续帧中强化海滩相关的标记:如果有人在水中,大概可以标记为游泳;而闭眼的场景,可能是在晒太阳。
同样,如果场景是一个超市,有人手拿培根,应该被标记为购物,而不是做饭。
我们想做的事情,是让模型追踪世界的状态。
看到每个图像后,模型输出一个标签,并更新其对世界的知识。例如,模型能学会自动发现和追踪信息,例如位置、时间和电影进度等。重要的是,模型应该能自动发现有用的信息。
对于给定的新图像,模型应该融合收集而来的知识,从而更好的工作。
这样就成了一个循环神经网络RNN。除了简单的接收一张图片返回一个活动标记之外,RNN会通过给信息分配不同的权重,从而在内部保留了对世界的记忆,以便更好的执行分类任务。
RNN的数学原理如图所示:
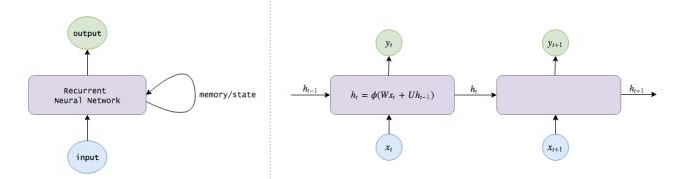
通过LSTM实现长期记忆
模型如何更新对世界的认知?到目前为止,还没有任何规则限制,所以模型的认知可能非常混乱。这一帧模型认为人物身处美国,下一帧如果出现了寿司,模型可能认为人物身处日本……
这种混乱的背后,是信息的快速变换和消失,模型难以保持长期记忆。所以我们需要让网络学习如何更新信息。方法如下:
增加遗忘机制。例如当一个场景结束是,模型应该重置场景的相关信息,例如位置、时间等。而一个角色死亡,模型也应该记住这一点。所以,我们希望模型学会一个独立的忘记/记忆机制,当有新的输入时,模型应该知道哪些信息应该丢掉。
增加保存机制。当模型看到一副新图的时候,需要学会其中是否有值得使用和保存的信息。
所以当有一个新的输入时,模型首先忘掉哪些用不上的长期记忆信息,然后学习新输入有什么值得使用的信息,然后存入长期记忆中。
把长期记忆聚焦到工作记忆中。最后,模型需要学会长期记忆的哪些部分立即能派上用场。不要一直使用完整的长期记忆,而要知道哪些部分是重点。
这样就成了一个长短期记忆网络(LSTM)。
RNN会以相当不受控制的方式在每个时间步长内重写自己的记忆。而LSTM则会以非常精确的方式改变记忆,应用专门的学习机制来记住、更新、聚焦于信息。这有助于在更长的时期内跟踪信息。
LSTM的数学原理如图所示:
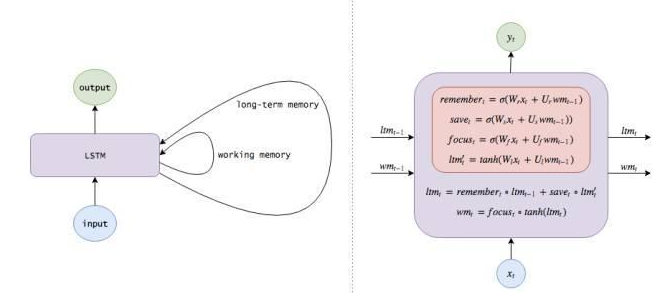
卡比兽
我们不妨拿《神奇宝贝》中的卡比兽对比下不同类别的神经网络。
神经网络

当我们输入一张卡比兽被喷水的图片时,神经网络会认出卡比兽和水,推断出卡比兽有60%的概率在洗澡,30%的概率在喝水,10%的概率被攻击。
循环神经网络(RNN)
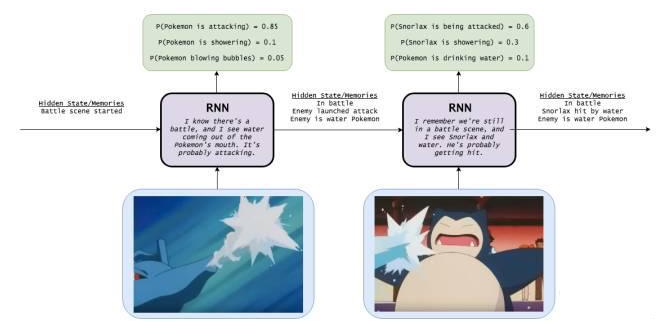
在隐藏状态(Hidden State)为“战斗场景开始”的情况下输入神奇宝贝喷水进攻图,RNN能够根据“嘴中喷水”的场景推测图一神奇宝贝是在进攻的概率为85%。之后我们在记忆为“在战斗、敌人在攻击和敌人是水性攻击”三个条件下输入图片二,RNN就会分析出“卡比兽被攻击”是概率最大的情况。
LSTM
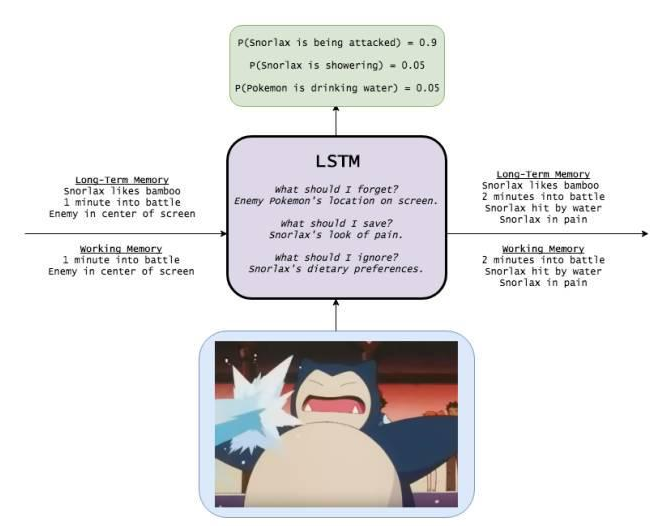
在长期记忆(Long-Term Memory)为“卡比兽喜欢吃竹子”、“每个战斗回合为一分钟”和“敌人在屏幕中央”,工作记忆(Working Memory)为“每个战斗回合为一分钟”“敌人在屏幕中央”的情况下,输入卡比兽被喷水的图片,LSTM会选择性处理一些信息。它选择性记忆了卡比兽的痛苦的表情,忘掉了“屏幕中央的是敌人”这条信息,得出卡比兽被攻击的可能性最大。
学会编码
有一种字符级的LSTM模型,可以通过输入的字符级序列来预测下一个可能出现的字符。我将用这种模型向大家展示LSTM的用法。
虽然这个方法看起来不成熟,但不得不说字符级的模型使非常实用,个人觉得比单词级模型还要实用一些。比如下面这两个例子:
1. 假设有一种代码自动填充器足够智能,允许手机端编程。
理论上讲,LSTM可以跟踪当前所用方法的返回类型,更好地建议返回哪个变量;也可以通过返回错误类型告诉你程序是否有bug。
2. 像机器翻译这种自然语言处理程序通常很难处理生僻术语。
怎样才能把之前从未见过的形容词转换成相应的副词?即使知道一条推文是什么意思,但怎样为它生成标签?字符级模型就可以帮你处理这些新出现的术语,不过这也是另外一个领域研究的事情了。
所以在一开始,我用亚马逊AWS弹性计算云EC2的p2.xlarge在Apache Commons Lang代码库训练了三层LSTM,几个小时后生成了这个程序:

虽然这段代码并不完美,但已经比我认识的很多数据专家编写的代码优秀了。从这里我们可以看出LSTM已经学会很多有趣且正确的编码行为:
可以构建class:优先放许可证,之后是程序包和导入包,再之后放注释和类别定义,最后是变量和方法。它也知道如何创造方法:需要遵循正确的描述顺序,查看装饰器是否处于正确的位置,以适当的语句返回无类型指针。重要的是,这些行为还跨越了大量的代码。
可以跟踪子程序和嵌套级别:如果语句循环总是被关闭的话,缩进处理是一个不错的选择。
它甚至知道如何创建测试。
此模型到底是怎样做到上面这些功能的呢?我们可以看几个隐藏状态。
这是一个神经元,看起来它似乎在追踪代码的缩进级别。在神经元以字符为输入进行读取,例如试图生成下一个字符的时候,每个字符都根据神经元的状态被标记了颜色,红色表示负值,蓝色表示正值。

这里有一个可以计算两个标签距离的神经元:
还有一个在TensorFlow代码库中生成的不同3层LSTM的有趣输出结果:

研究LSTM的内部结构
上面我们了解了几个隐藏状态的例子,不妨再聊得深入一些。我在考虑LSTM cell和它们的其他记忆机制。或许它们之间也存在令人惊叹的关系。
计数
为了探究这个问题,我们需要先教LSTM学会计数,所以我生成了下面这个序列:
aaaaaXbbbbb
这串序列中,在N个a之后跟着一个定界符X,之后又跟着N个字符b。在这里,1<=N<=10。我们用此序列训练带有10个隐藏神经元的单层LSTM。
正如预期的那样,LSTM在其训练范围内表现良好,甚至可以生成一些超过了训练范围的东西。
aaaaaaaaaaaaaaaXbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbbb
aaaaaaaaaaaaaaaaaaaXbbbbbbbbbbbbbbbbbb
我们期望找到一个隐藏的状态神经元计算a的数量:
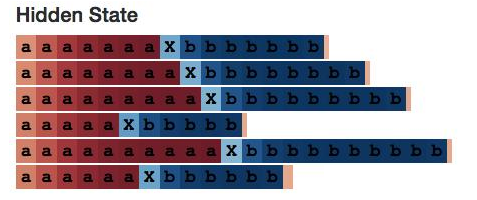
为此我还专门构建了一个小型网页应用,它不仅可以在刚刚的基础上计算a的数量,还能计算b的数量。
此时cell表现很相似:

还有一件有趣的事情,工作记忆看起来像一个长期记忆的增强版,这在一般情况下是正常的吗?
答案是肯定的,这也和我们期望的完全一样。因为长期记忆被双曲正切激活函数限制了输出内容。下面是10个cell状态节点】的总览,我们可以看到很多代表接近0值的浅色cell。
相比之下,这10个工作记忆的神经元看起来更专注,1号、3号、5号和7号在序列的前半部分看起来都是0。
那我们再看看2号神经元,这里给大家展示一些备用记忆和输入门(Input Gate)。它们在神经元的每半部分都是稳定的——就像神经元在每个步骤都在计算a+=1或b+=1一样。
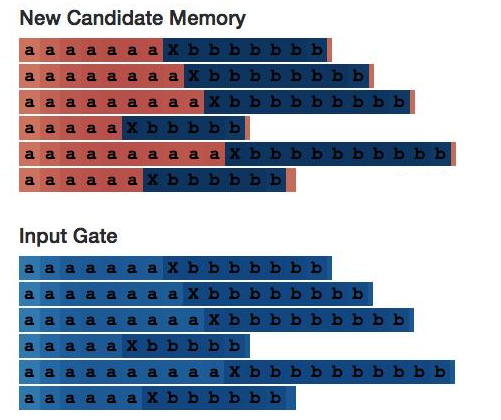
最终,我们得到了所有神经元的内部结构:

如果你也想为不同的神经元计数,可以看看这个可视化工具。
可视化工具链接:
http://blog.echen.me/lstm-explorer/#/network?file=counter
伯爵
还记得美国公共广播协会(PBS)制作播出的儿童教育电视节目《芝麻街》,里面有一个魔方吸血鬼样子设计的玩偶,叫伯爵。他喜欢数数,对计算机的兴趣没有边界。我就把这一部分的标题命名为伯爵好了。
现在我们看一个稍微复杂一点的计数器,这一次我生成了序列化的表单是:
aaXaXaaYbbbbb
上面这串序列的特点是N个a和X任意交叉排列,再加入一个定界符Y,最后加入N个b。LSTM仍需计数a的数目,这次也同样需要忽略X。
完整的LSTM链接:
http://blog.echen.me/lstm-explorer/#/network?file=selective_counter
我们希望得到遇到X时输入门是0的计数神经元。

上面就是20号神经元的cell状态。在还没有到达定界符Y时它会一直增大,之后一直递减直到序列的末尾——就像它计算的是num_bs_left_to_print变量,根据a的增量和b的递减不断变化。
它的输入门确实忽略了X:
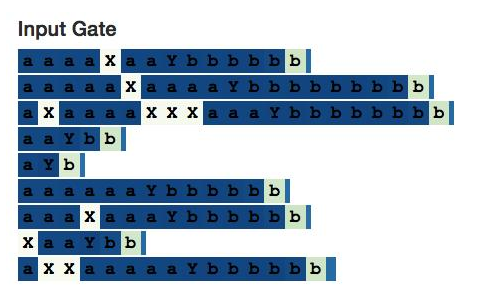
有趣的是,备用存储器完全激活了不相关的定界符X,所以我们还是需要一个输入门。(如果输入门不是架构的一部分,想必神经网络将学会用其他方式学会忽略X)
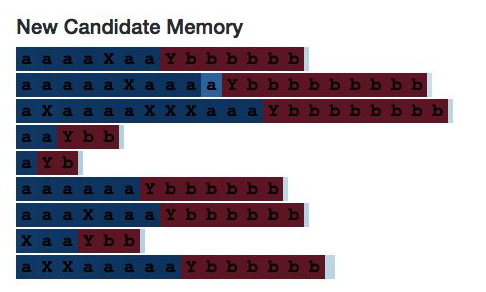
那我们继续看10号神经元。
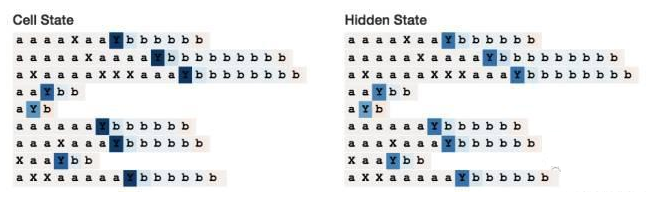
这个神经元很有意思,因为它只有在读取定界符Y时才可以激活,但它仍然试图编码目前在序列中看到的a。这很难从图中看出,但当读取到Y属于有相同数量的a的序列时,所有的元胞状态都是几乎相同的。可以看到,序列中a越少,Y的颜色越浅。
记住状态
接下来,我想看看LSTM是如何记住元胞状态的。我在再次生成一些序列:
AxxxxxxYa
BxxxxxxYb
在这个序列中,A或B后面可以接1-10个x,之后接入定界符Y,最后以开头字母的小写结尾。这种神经网络需要记住序列是否为一个A或B序列状态。
<p style="padding: 0px; border: currentColor; border-image: none; color: rgb(34, 34, 34); line-height: 22px; font-family: "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", "Helvetica Neue", Arial, sans-serif; margin-top: 0px; margin-bottom: 0px; list-style-type: none
